With apologies to the late, great Prince…RIP.
You’ve all heard the hype and bluster about the Cloud. As a term, I smirk about it being a “new” concept: the AT&T reps who used to call on me at Blue Cross Blue Shield of Oklahoma were using it in 2000. It’s old telco jargon that’s now been co-opted since telcos have embraced the IP world.
But the practical applications of the Cloud have made “seasoned” IT dudes like myself feel a bit of the old excitement, similar to the thrill of working with the original cloud, the Internet, back in the 1990s.
Moving mission-critical resources, or copies of them, out beyond our server rooms offers a freedom from the old duty of shoveling coal into the engines. Rather than merely being a caretaker of 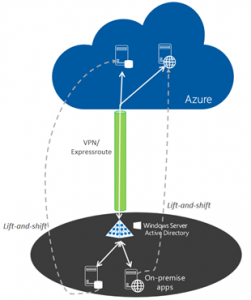 physical boxes and infrastructure, you can be more strategic and begin to think about how to dial up additional resources, or at the very least make more resources available to staff and stakeholders, where and when they want to work.
physical boxes and infrastructure, you can be more strategic and begin to think about how to dial up additional resources, or at the very least make more resources available to staff and stakeholders, where and when they want to work.
Make no mistake: we haven’t been standing still — we’ve been using Office365 since April 2013. Our VOIP phone system’s back office is in Philadelphia. And we recently made the switch to SharePoint from our ancient file server (vmware via ESXi 3.5! Windows Server 2003!). Many of my private sector colleagues have embraced the Azure cloud, so it’s worth seeing if we cost-conscious nonprofits can do it as well.
Plus: since the NTech Collaborative program is under my purview, learning how to do this to assist our partner nonprofits is a good thing.
So after some failed attempts to replicate 2 mission-critical VMs over to our Disaster Recovery failover site, we’ve decided to point our VMs to the Azure cloud. My associate Pat McCarty at Continuum Energy Services was a prime mover in assuring me that “Yes, you can do this and it won’t break the bank.”
Setting up an Azure account was easy, as we already had the bones in place from our Office365/SharePoint migration. It was easy to set up the Azure Site Recovery service on our Hyper-V server so it could easily begin shooting our guest VMs to the great beyond. The great thing about the Azure Site Recovery is VM replication is basically free, until you use it. So it’s a perfect product for us — our plan is to eventually deploy a server of similar horsepower to our DR site, so that in case we need to we can pull the VMs down an on-premises box if necessary. Or not: depending on the nature of our crisis it might be just as easy to work from the Cloud.
I’ll spare you the LONG and involved tale of what didn’t work (repeatedly), but the short form is that our Accounting system (GreatPlains — a 50Gb VM) worked without a hitch, and our main campaign database (Andar: ~220Gb) did not.
We suspected that our Dual WAN bandwidth (10x10Mbps from AT&T, and 50x10Mbps from Cox) wasn’t sufficient — too much latency. We ran the Azure bandwidth calculators, and it sure enough appeared that we were just shy of sufficient bandwidth. So we moved to the next size up from Cox: 100x20Mbps, with is approx. $70/month more.
That’s not a lot; but remember we’re a community funding organization — keeping costs low to shift as much resources out to our partner nonprofits is in our DNA.
The additional bandwidth did it: now we have 5 days of successful replications of both servers to Azure Site Recovery at 15-minute increments.
It’s a great first step, and gives us redundant access to complete VMs. While it would be nice to move to having the apps themselves securely hosted and abstracted from the virtual boxes, that requires change on the part of our database developer.